


Fat Tailed Thoughts: Teaching Digital Machines to Understand Paper Documents
Fintech's dirty secret: it takes people to understand data on paper. A lot of people.

Hey friends -
My apologies for this letter not being published on the regular Wednesday morning schedule. While others are enjoying 20 Days of Christmas, I'm experiencing 20 Days of Jury Duty. It’s more time-consuming than I had anticipated. Please forgive me if other letters this month are also later than usual.
Make sure to check out last week’s podcast! We revisit a topic from a previous letter - benchmarking the size and growth of the crypto market relative to GDP against oil, gold, and stocks. The data doesn't lie - crypto is truly in a league of its own!
This week we're tackling a topic near and dear to my heart, deep in the bowels of financial services where I've spent significant time. It’s the dirty secret of fintech: for all the talk about technology, there is a truly staggering number of people who are involved in highly manual tasks. Nowhere is this more true than when the data is stuck on paper but the machines that analyze it need it to be digitized.
In this week's letter:
Analog inputs in a digital world: the challenges of paper, how they're solved, and where the technology's going
An exemplary articulation of an investment philosophy, Coinbase misleads investors on ETFs, and more cocktail talk
Corpse Reviver #1, a cocktail "to be taken before 11AM, or whenever steam or energy is needed"
Total read time: 14 minutes, 41 seconds.
Key Takeaways
Most financial data on individuals is stored on paper or in PDFs, formats that innovative fintech startup technology can’t read.
OCR is the technology used to covert this analog data to digital so it can be used.
OCR is inaccurate and brittle at best - that means lots and lots of manual effort.
“Smarter” technology that uses artificial intelligence and other techniques isn’t always better. Sometimes “dumber” technology with manual review is a better solution. It depends on the problem being solved.
The data collected by OCR companies is extraordinarily valuable, setting them up for major new opportunities.
Machines Can't Read
Imagine you and I wanted to launch a new financial services startup that will loan money to consumers. One of the most basic - and most critical - challenges will be our ability to determine if the loan applicants will actually pay back the loans.
The beauty of technology is that it can crunch through lots and lots of data. Our startup's data-crunching machine will determine if the applicants will pay back their loans by analyzing data like individuals' income, spending habits, and whether they pay their bills on time. But first, we have to get ahold of all this data. That's where stuff gets tricky.
The data doesn't actually exist.
At least not in such a way that our data-crunching machine can make use of. It mostly lives on pieces of paper like printed-out bank and credit card statements. Paper and pictures contain analog data. Machines understand digital data. Something has to translate from paper to digital.
Welcome to the world of Optical Character Recognition.
Teaching Machines to Read
The fundamental challenge with a piece of paper or a "digital" PDF is that those ink marks we recognize as letters contain no instructions for the computer. The computer quite literally doesn't know how to read them.
This problem is extremely common across financial services because of the volume of paperwork. Just think about how much paperwork you deal with across your credit card statements, bank statements, and tax forms. When you multiple that by millions of people, it becomes a truly staggering amount of paper. A bank I previously worked with explained that they spend over $20 million per year on printer ink alone.
The basics of every computer system used to "read" the paper are the same. The systems stores ink blotch patterns in its memory. Those patterns are associated with letters and words. Each pattern is just a collection of pixels, such as knowing that a pattern of pixels laid out with a horizontal line atop a vertical line is probably a "T".
The systems also have a scanner-esque component that takes pictures of the documents and compares the ink blotches to what it has stored in its memory. When it finds matches - like for the letter "T" - it records the match. It's this process that gives rise to the name for these technologies - optical character recognition - or OCR for short.
The challenge of using technology to convert data on paper to digital breaks down into two considerations:
Document structure - whether the text is read left to right or right to left; if the text is in columns or across the full page; how to decipher tables, graphics, and their associated captions; and other similar features
Document content - the actual data you'd like to extract including text and numbers and the context in which they were extracted, like knowing the order the letters came in so you can recreate words
Document content can be broken down again. It's one challenge to extract the data, such as converting a handwritten note to digital words. It's often a different challenge for the computer to "understand" the digitized data. For instance, if a form field labeled First Name is filled in with "Jared," then the computer should store both the value "Jared" and denote that it is the First Name. We call the latter metadata - additional data that describes the data we care about.
Metadata can become voluminous very quickly. Recording that Amazon Web Services always appears capitalized as a triplet is just the start. We might also record its place in the sentence, which paragraph, and the location on the page. In the case of Amazon Web Services, such metadata helps the machine differentiate between the capitalized brand name "Amazon Web Services" and web services in the Amazon. Digital storage is cheap and metadata doesn't take up much room, so we generally try to gather as much metadata as possible and figure out if it's useful later.
Different types of paper documents present different challenges. Let's look at a couple of examples.
Structured text
Structured text, like forms, is notoriously difficult for humans. We're bad at understanding where to fill in answers. Just look at the signatures from Japan's surrender at the end of World War II.

Canada's representative signed in the wrong place! It created a hilarious ripple as each subsequent representative had to amend the document so they too could sign.
While such forms are complex for humans, they're more straightforward for computers.

Forms like the I-9 come with a massive built-in advantage for computers - the form structure is the same, every time regardless of the answers to the questions. Where there is consistency, we can build rules so the machines can understand the document structure:
Big boxes contain text that we want to extract
Lines to the right of the text contain text we want to extract
Little boxes are booleans - if they're filled in it's true
To help the machine extract data, we can divide the page into a Cartesian plane (X + Y axes). We'll label coordinates such as (10,14) and program the machine to record the ink blotches found there as Last Name (Family Name). This works even if the page was scanned in crooked. We can use markers - like the seal in the upper left and the page number in the bottom right - to help the computer reorient as needed.
It gets more complicated when we don't know what to expect.
Unstructured text
Unstructured text is relatively easy for us humans to understand but devilishly difficult for computers, the reverse of structured data. Regulations are good examples of unstructured text and are the problem I spent significant time solving.

As people, a couple of things are immediately apparent:
The text is in English - it should be read left to right, top to bottom
The header and footer are distinct from the rest of the page - the bulleted list at the bottom should continue with the bullet on the next page, not with the header from that page
The big, bold text throughout the page are headers and sub-headers
The text sections grouped together are paragraphs
The bulleted lists are associated with the paragraph immediately preceding them
That's a lot of structural elements, but it is by no means an exhaustive list. We could have additional structural elements like sub-bullets, numbered lists, and block quotes as well. All of this needs to be programmed into the computer.
Unlike with a form, the computer also needs to "understand" the structure without the aid of a pre-built graph to extract content. Content starts with the basics - recognizing the shape of the letters, punctuation, and symbols such as §. It gets more complex as we want the system to error-check and make sure what it "thinks" it sees are actual words. There's as much art as science here. While a dictionary can help, acronyms like TILA and formal names like Regulation Z require a more complex understanding of the content.
This really becomes a pain with tables.
Tables
Tables don't come with "how to read" instructions. The first row may be a header to data displayed in rows, or, the first column may be a header to data displayed in columns. Or, we might even have a combination of the two!
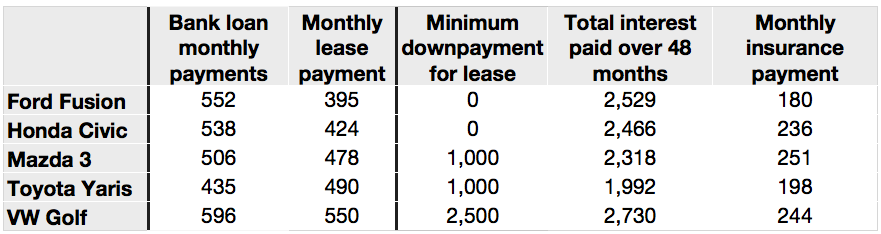
This is a good example of a table that can appear straightforward in both structure and content but be a nightmare. Some of the potential challenges include:
The computer has to read the first column AND have a dictionary of car names and manufacturers to determine that this about cars
The computer has to read the first row AND have a dictionary of financial terminology to determine this is about car payments
We have to tell the computer that bolding and coloring signifies header rows and columns
The computer has to read the column headers to learn that three of the columns are monthly amounts, one of the columns is a one time charge, and the last column is a total for an amount paid monthly over 48 months
Commas are used to delineate thousands in the US but decimal amounts in Europe
While we can build computers to understand this table, imagine if this was included in a document with many other tables each of which had its own nuances.
Or imagine if this was part of a more complex document.
One-off documents
When you combine all these problems in a single document, they become very difficult to solve.

Here you have a one-off form that's specific to a single company. It includes a freeform address section, fill-in-the-blanks that appear on the left of the text and in the middle of sentences, booleans structured as paragraphs... in short, a mess. This will be a real pain to have a computer understand.
But there's always an alternative - people.
From Paper to Digital
Rather than use technology, a company can pay rooms full of people to read the documents and retype the answers into databases. Most firms outsource this to specialist companies based in India.
The specialists usually charge by the page for standardized forms or by kilo-character (per 1000 characters) for unstructured text. There are additional charges for accuracy, such as a contract that guarantees 99.9% accuracy and includes an optional upcharge to get 99.999% accuracy. Keep in mind here - while 99.999% accuracy sounds impressive, it means you should expect a mistake every 10,000 characters. That's a mistake every 3.5 pages!
How do we get more accuracy in a people-based system? More people! In the banking compliance world, we call this checkers checking checkers checking checkers. The more layers of review, the higher the degree of accuracy that can be guaranteed.
These layers of manual review and a pricing model based on volume create incentives for the specialists to use machines and automate people out of the process. But it's not just the traditional startups anymore - startups have also woken up to the opportunity.
Rise of the machines
The technologies these startups have built have varying degrees of smarts. Those smarts typically vary along the same document structure and document content challenges highlighted earlier. Smarter systems are not always better - it depends on the problem we're trying to solve.
Simple, stupid machines
The most simple systems scan documents regardless of layout and pull out all of the known words. Any contiguous group of letters that is not found in the machine's dictionary is flagged for manual review. If a letter overlaps with a line on the page and can't be accurately deciphered, it'll be flagged.

Such technology is regularly used in trade finance, the financial services business where global trade is insured and sellers are assured they'll be paid. A bill of lading, like the one above, is a key document that describes the contents being shipped.
Trade finance can be highly risky. There is financial risk alongside a world of sanctions and tariffs to navigate. You don't want a system that's 99.999% accurate - you need 100% accuracy, every time.
The technology used is deliberately brittle - most of the words it flags as "not found in the dictionary" are false positives. At the bottom of the page, you'll notice the signature covers the text "CANADA INC. AS AGENTS FOR." While we as humans can decipher the text, the technology will flag it for manual review. This isn't poor design - it's exactly what the system is designed to do. The financial services company wants a person to review anything with even small probabilities of being incorrectly read by the machine.
One trade finance bank I worked with reviews hundreds of thousands of pages of trade documentation per month. Their system not only detects words and names but also compares the content to terrorist watch lists. In a single month, the system flagged over 10,000 "hits" from the OCR system that had to be manually reviewed. Only 3 were accurate.
Artificial intelligence for word recognition
Most uses of OCR don't require the accuracy of trade finance. If you're trying to digitize a book, for instance, you can generally tolerate more mistakes.

I searched for tortoise in Google's digitization of The Tortoise and the Hare, and their technology successfully identified the word. With older books or when pages are blurry, the technology will have a more difficult time.
Artificial intelligence has helped make great strides here. The challenge is that we need training data to teach the machine. Training data is the formal term for a straightforward concept - if the machine is going to learn how to identify tortoise correctly every time, it needs a lot of examples of tortoise in different fonts, in varying degrees of blurriness, and so forth. The machine also needs to be told - manually - that each of the examples is tortoise. With that training dataset, it can use artificial intelligence to "guess" at new incoming scans of tortoise that are different than the training data, but close enough that it can recognize the word with high degrees of precision.
How does Google get the training data? Well, you know those obnoxious "prove you're not a robot by guessing the letters" we fill out online?
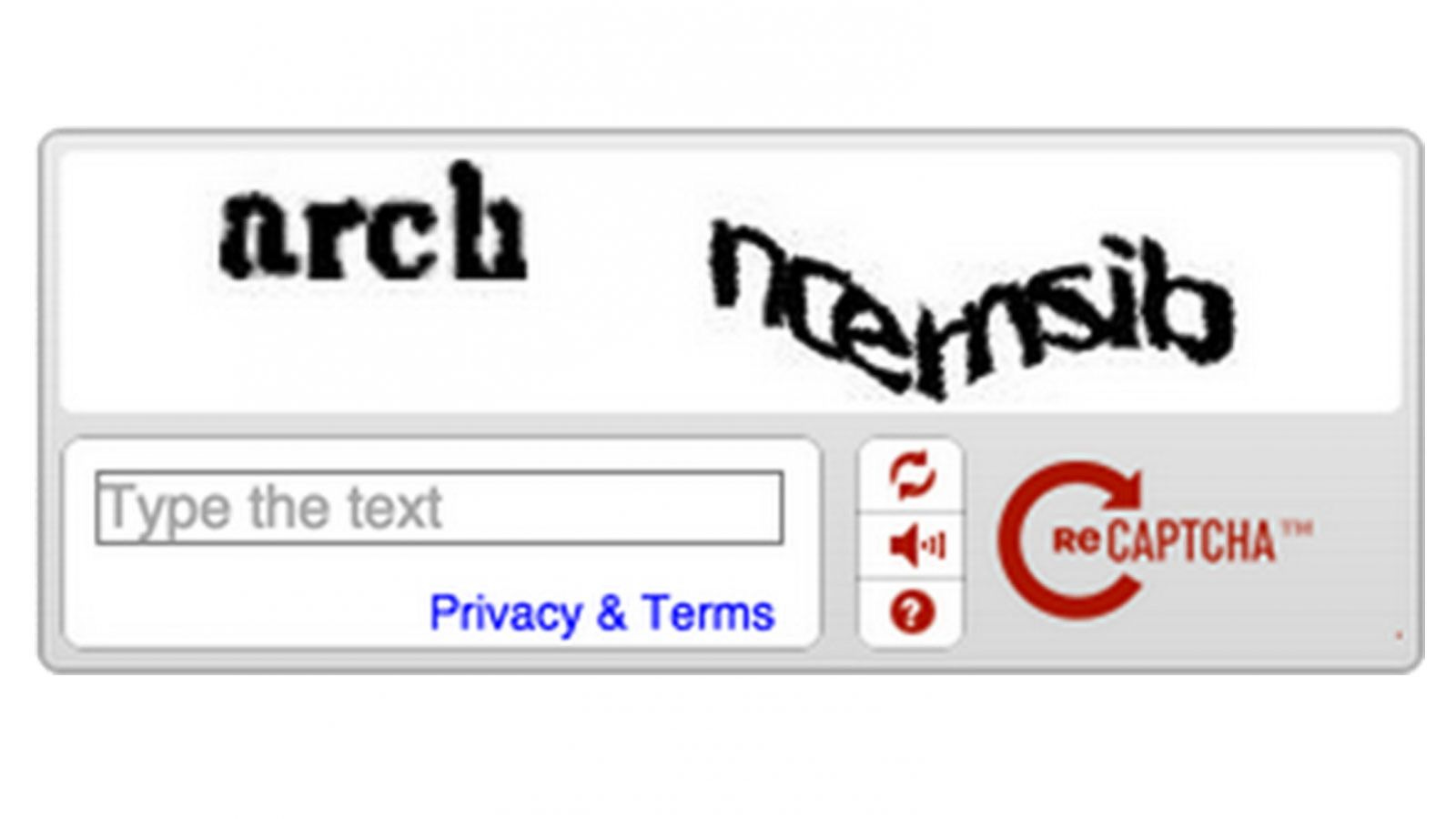
You're creating training data for Google which they feed back into their OCR technology so it does a better job recognizing words! The new ones involving pictures ("identity all of the stop signs") are similar but for Google Maps.
Artificial intelligence for document structure
In the case of forms where we know where to look for the data, humans will annotate a sample form to instruct the system from where on the page to extract data. Annotating is quite similar to highlighting. Think drag-and-drop boxes and a form field where you input "this box is labeled First Name."

Most OCR technology has a rules-based understanding of document structure - they follow exactly what the annotations indicate. Some cutting-edge technologies use artificial intelligence to "learn" how to read forms they have never seen before. This can work well with forms that vary slightly but have predictable content like bank statements.
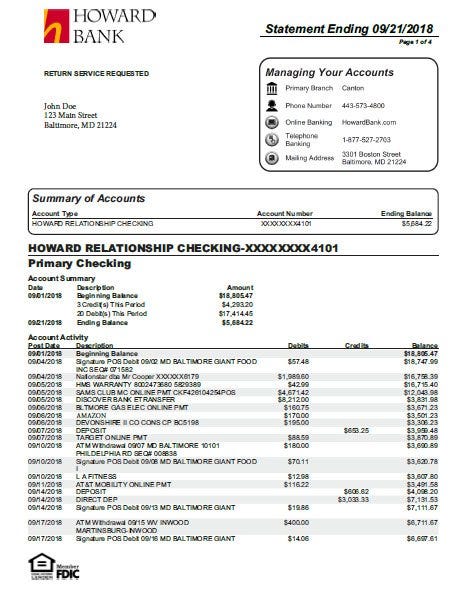
Even if we gathered ten more bank statements, they will look somewhat similar. Each will have a similar layout that includes the account owner's name, their address, the period, and a table of the account activity during that period. Once humans have annotated a broad sample of bank statements to tell the technology what to look for, the technology can often "guess" at how to read a new statement with a novel layout.
It always comes back to people
This is why I call it fintech's dirty secret. In every example, people are intimately involved in translating analog paper and PDFs to digital data. So much for technology.
We have not yet invented a system that can do the job unaided. Once trained, these systems can analyze truly staggering quantities of data - Google alone has digitized over 25 million books. But all of the systems are staggeringly inaccurate, and none are general-purpose for all types of paper. Accuracy and adapting to novel document structure continues to be firmly a people problem.
And yet, even with these limitations, these OCR startups are extremely well-positioned to build valuable businesses that will stand the test of time.
The Future of OCR Startups
Just think for a moment about some of that data that's collected. A startup that's digitizing bank statements has data on all of the money moving in and out of someone's bank account. If the startup's analyzing credit card statements as well, they understand daily purchasing decisions. Add in tax forms, and you have an almost complete picture of most individuals' finances.
That's a powerful position to go beyond just digitizing data. An OCR startup can build a business by analyzing the data to create new, novel insights.
It’s where we’ll go next week!
Cocktail Talk
Rarely do I find investment analysts or managers whose philosophy aligns with mine. Even more rarely do I find that they can clearly articulate - in plain English - how they think about investing. Critical to any such articulation is an emphasis on what they won't do. Alex Morris of The Science of Hitting is one of those very rare individuals. I'm highlighting his recent writeup of his investment philosophy not as an endorsement of the philosophy itself - although it closely aligns with mine - but as an exemplary articulation of how he thinks, what he looks for in companies, and when he decides to invest. His letter is a masterclass. (The Science of Hitting)
One of the great joys of writing these letters is engaging with smart, interested readers who want to make better decisions as investors by learning more about financial services. You can imagine my dismay when I reviewed Coinbase's "education" on ETFs. The article fails to so much as get the basic definition of an ETF correct and is rife with similarly elementary errors. Coinbase serves 73 million users as the US's largest cryptocurrency exchange. The CEO announced in May "Coinbase Fact Check: Decentralizing truth in the age of misinformation." I humbly suggest they start by getting the basics of finance correct. (Twitter via yours truly)
In what should be a surprise to no one who regularly reads these letters, China continues to move forward with mass surveillance and abusing those who dare speak freely. Henan, a providence home to 110 million Chinese citizens, rolled out a new system to target journalists specifically including those from abroad. The new system includes both technologies for facial recognition and tracking as well as the operational changes necessary to support "Suspicious persons must be tailed and controlled, dynamic research analyses and risk assessments made, and the journalists dealt with according to their category." (The Guardian)
Dodd-Frank Section 1033. You probably haven't heard of it, but it has made a tremendous difference in your life. It is the reason why you can get analytics on your credit card spending from Mint, use Plaid to automagically connect your brokerage account to TurboTax, and engage with an entire universe of other financial technology offerings. Section 1033 requires banks and similar organizations to make your data available to third parties in an easy-to-consume digital fashion at your request. What it didn't do was enshrine protections as to what the third parties could do with your data once they got access. With multiple high-profile antitrust cases proceeding against major tech companies and a Biden executive order that expands data access under Section 1033, your data privacy is finally starting to get some much-needed attention. (JD Supra)
Your Weekly Cocktail
"To be taken before 11AM, or whenever steam or energy is needed"
Corpse Reviver #1
1.5oz Cognac
0.5oz Laird's Bonded Apple Brandy
1.0oz Dolin Sweet Vermouth
Maraschino cherry for garnish
Pour all of the ingredients, except for the cherry, into a mixing glass. Add ice until it comes up over the top of the liquid. Stir for 20 seconds (~50 stirs) until the outside of the glass is frosted. Strain into a coupe glass. Garnish with the cherry and enjoy!

The morning drinking instructions come from the much renowned Savoy Cocktail Book published in 1930. As the name implies, the Corpse Reviver #1 is part of a family of drinks designed to be had the morning after drinking too much. While I've made the most famous of the bunch - the Corpse Reviver #2 - many times, this one somehow escaped me. It ended up being a lovely drink for a cool fall evening. All three liquors are distinctive fruity but none overly sweet which creates a mellowness that's surprising given the alcohol-only make up. While I'm unable to recommend this as a breakfast drink, I thoroughly enjoyed it as an aperitif.
Cheers,
Jared